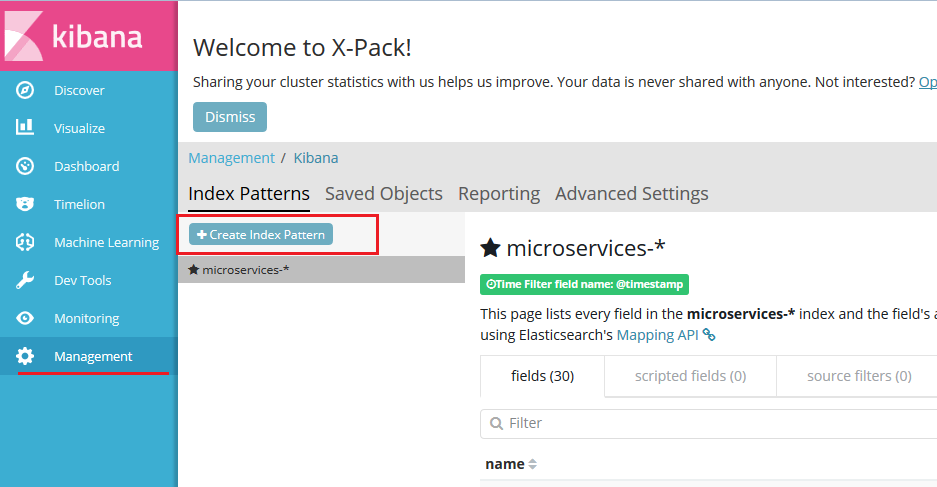
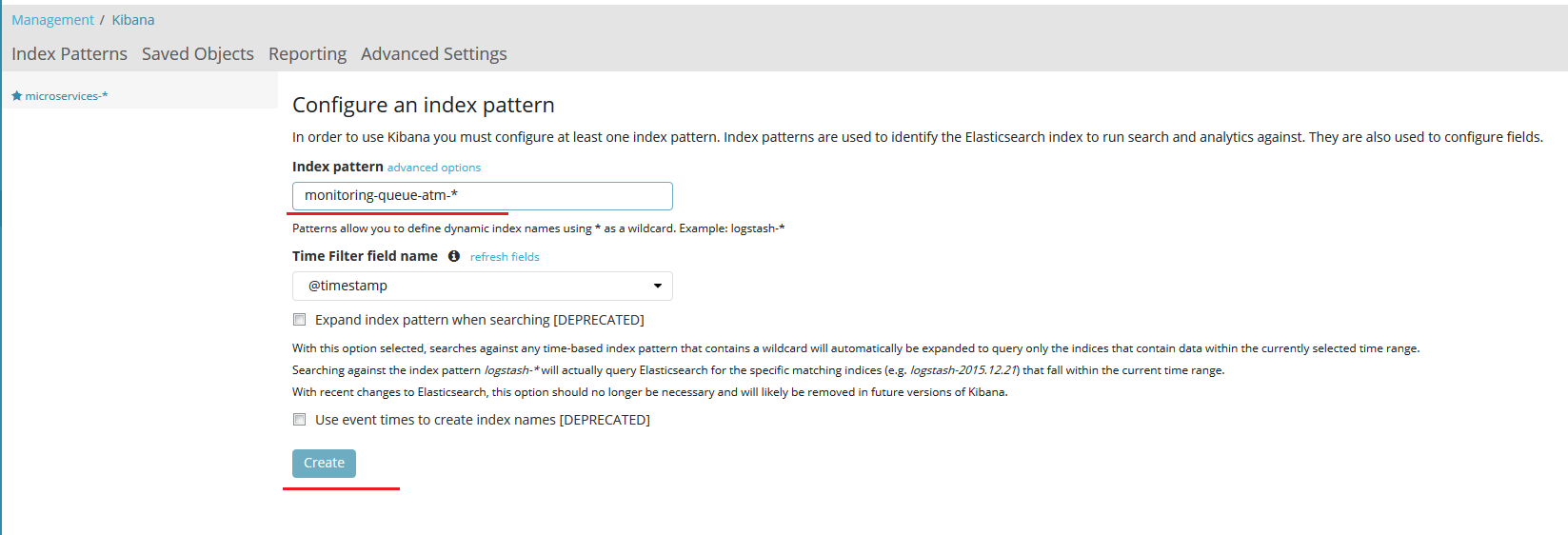
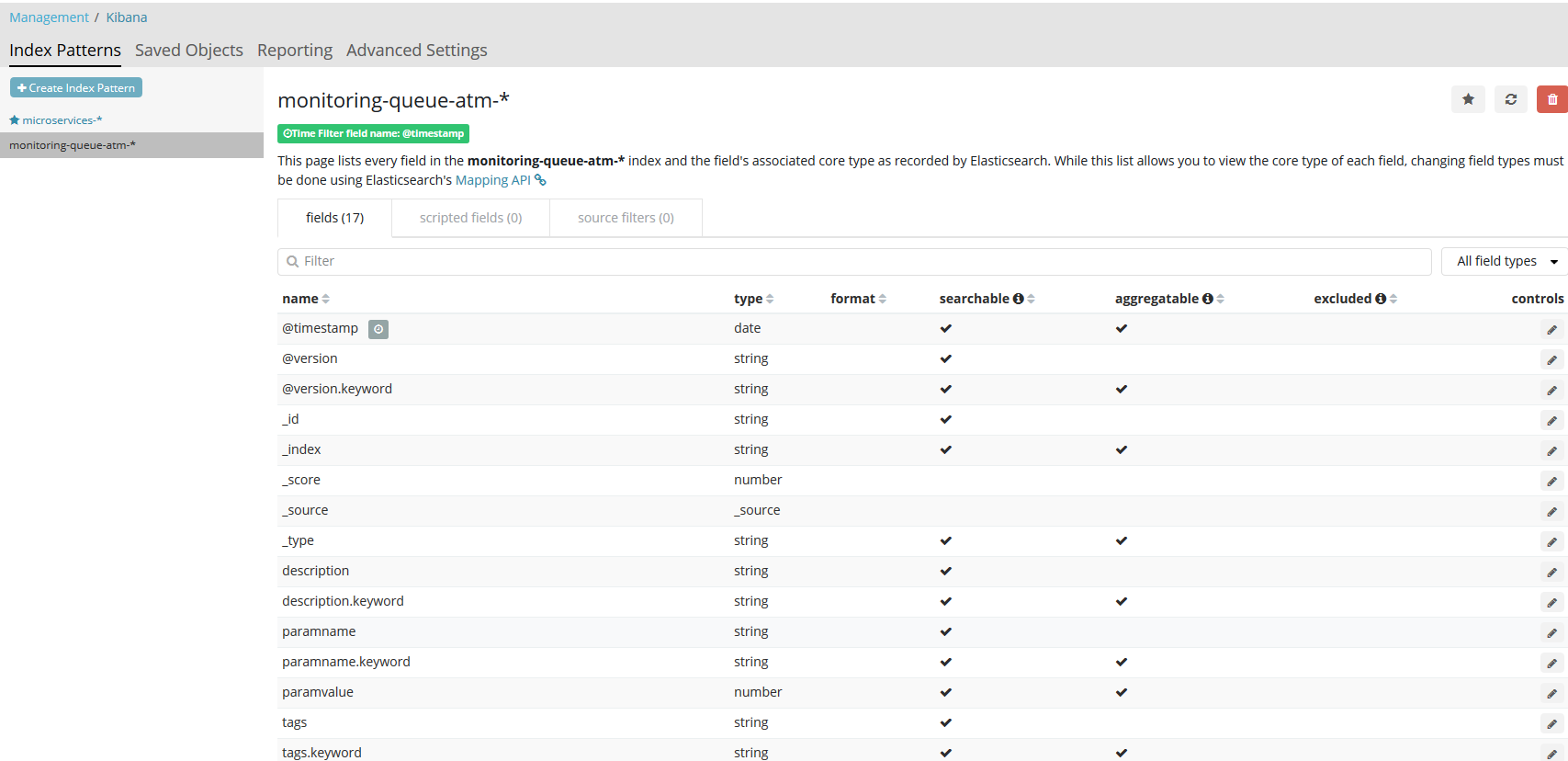
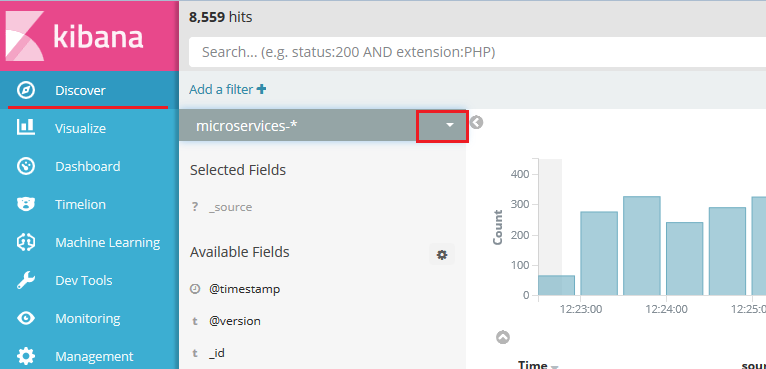
Для мониторинга соответствующего индекса в Kibana необходимо его настроить.
Заходим в пункт меню Management => Create Index Pattern:
В полe «Index pattern» указываем шаблон имени для отслеживаемого индекса. Если заданный индекс существует, то заполнится поле «Time Filter field name».
Для заданного имени будут автоматически сгенерированы поля.
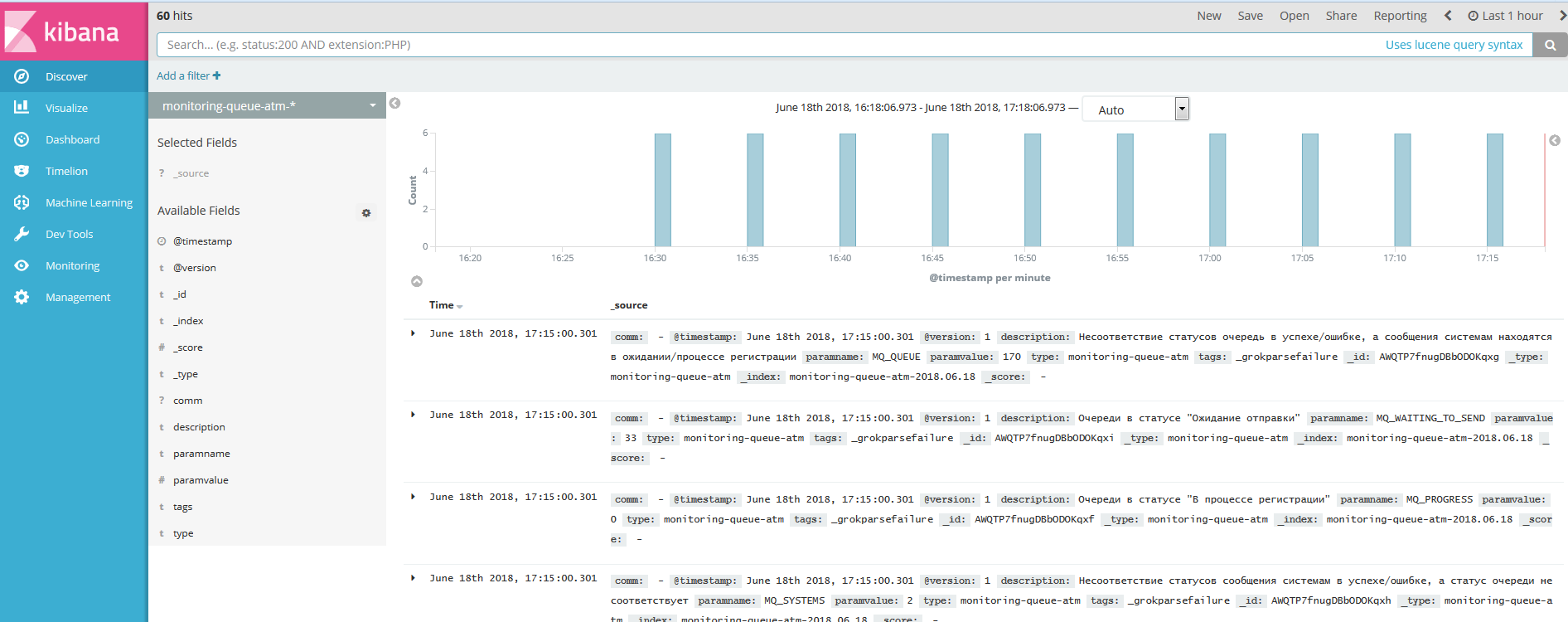
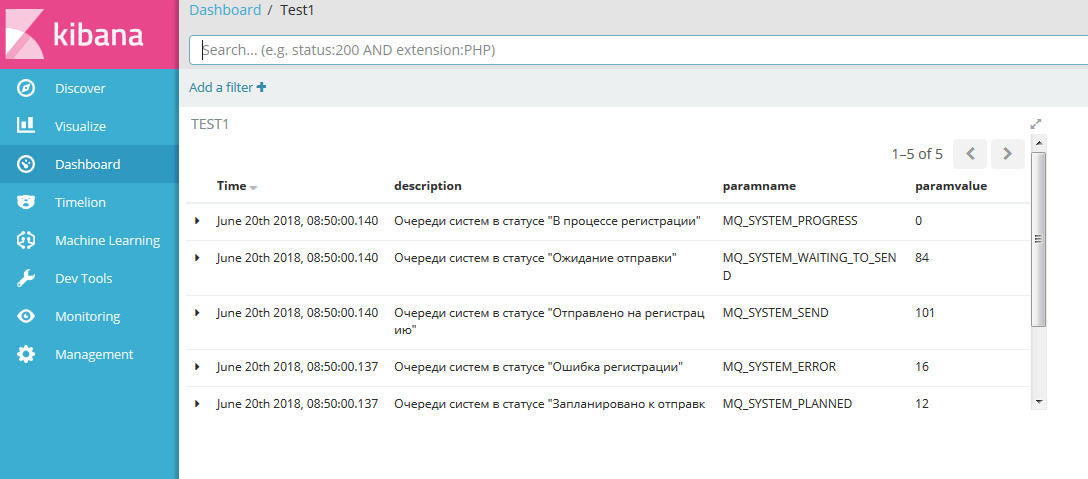
Для мониторинга информации по заданному индексу необходимо перейти в пункт меню Discover, и в выпадающем списке выбрать необходимый индекс
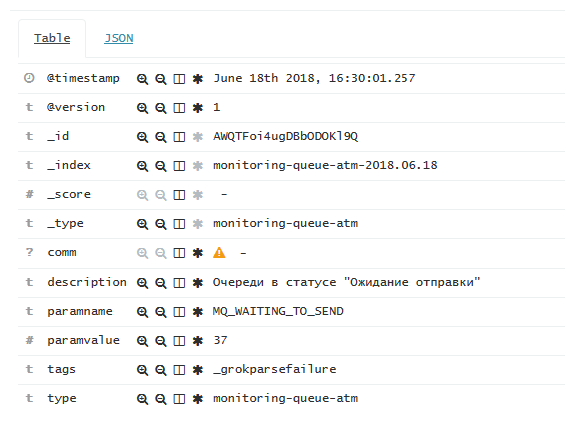
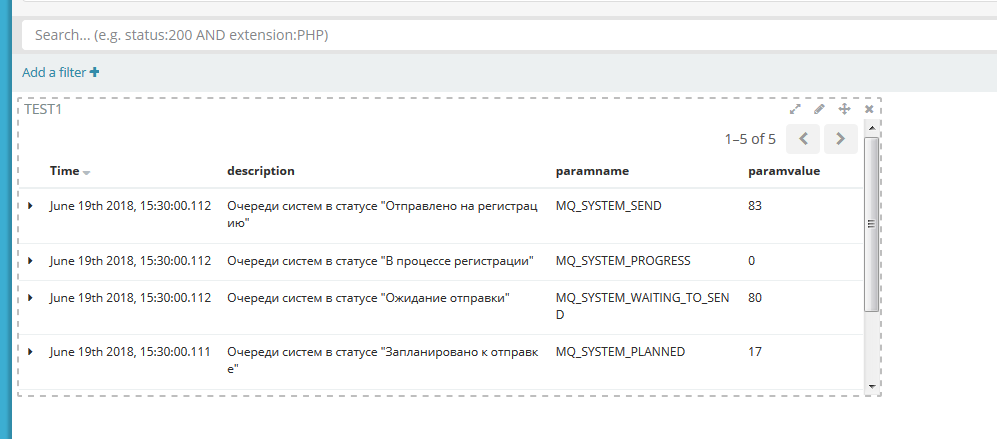
Каждая запись представлена в виде таблицы с настроенными в индексе полями:
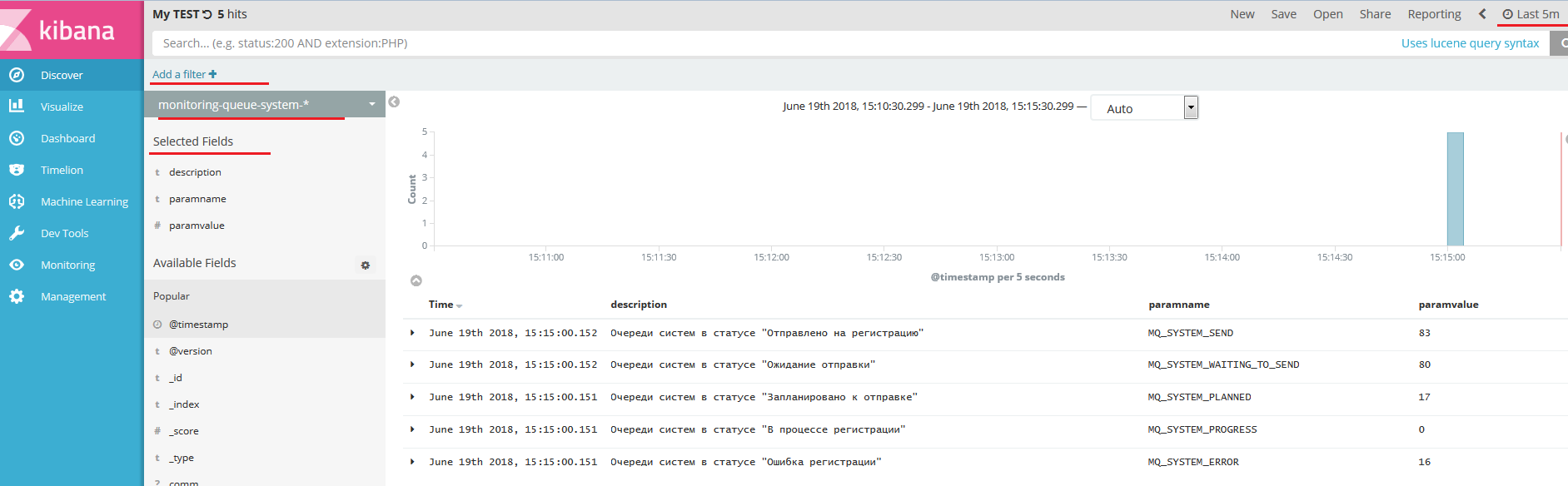
На вкладке Discover настраиваем необходимый фильтр, перечень полей для отображения.
Сохраняем результаты отбора. Переходим в пункт меню «Save», в поле «Save Search» указываем название для осуществленного поиска, указываем флаг «Save as a new search», и нажимаем на кнопку «Save» .
Переходим на вкладку Dashboard, нажимаем на кнопку «+» (Create new dashboard).
В открывшемся окне нажимаем на кнопку Add.
В открывшемся окне переходим на вкладку «Saved Search», и выбираем сохраненный ранее наш поиск.
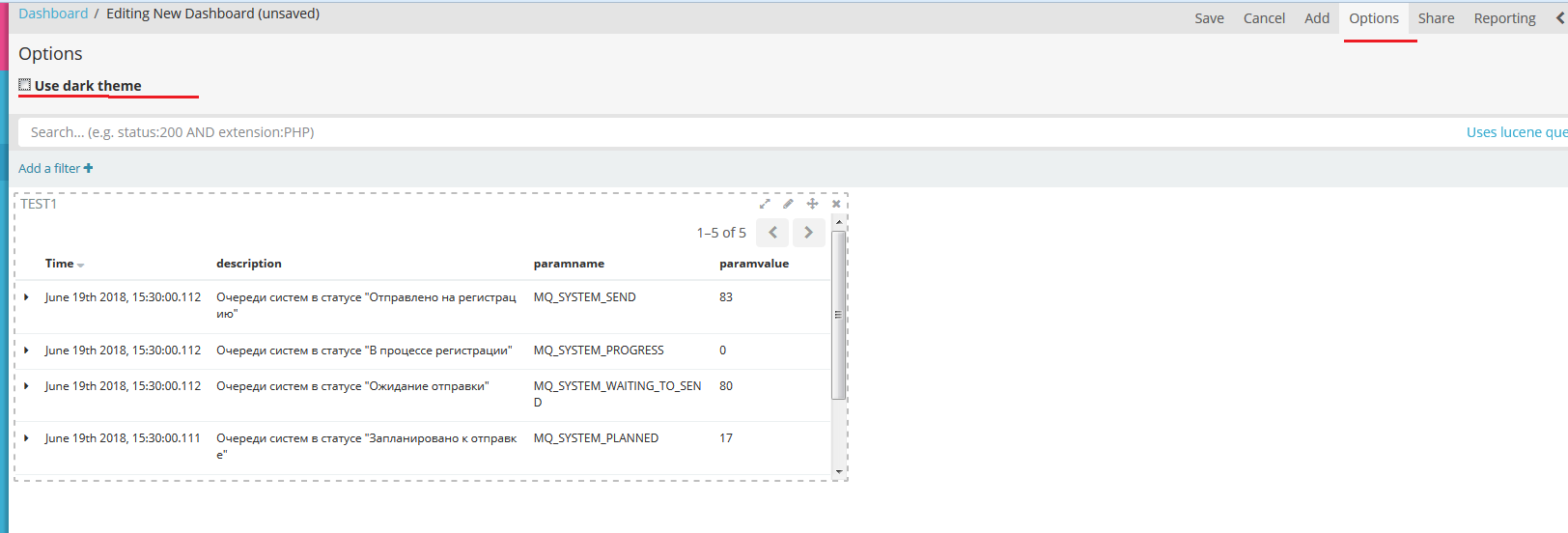
На выбранный поиск добавиться панель, у которой можно отрегулировать размер. На вкладке Options сменить тему оформления.
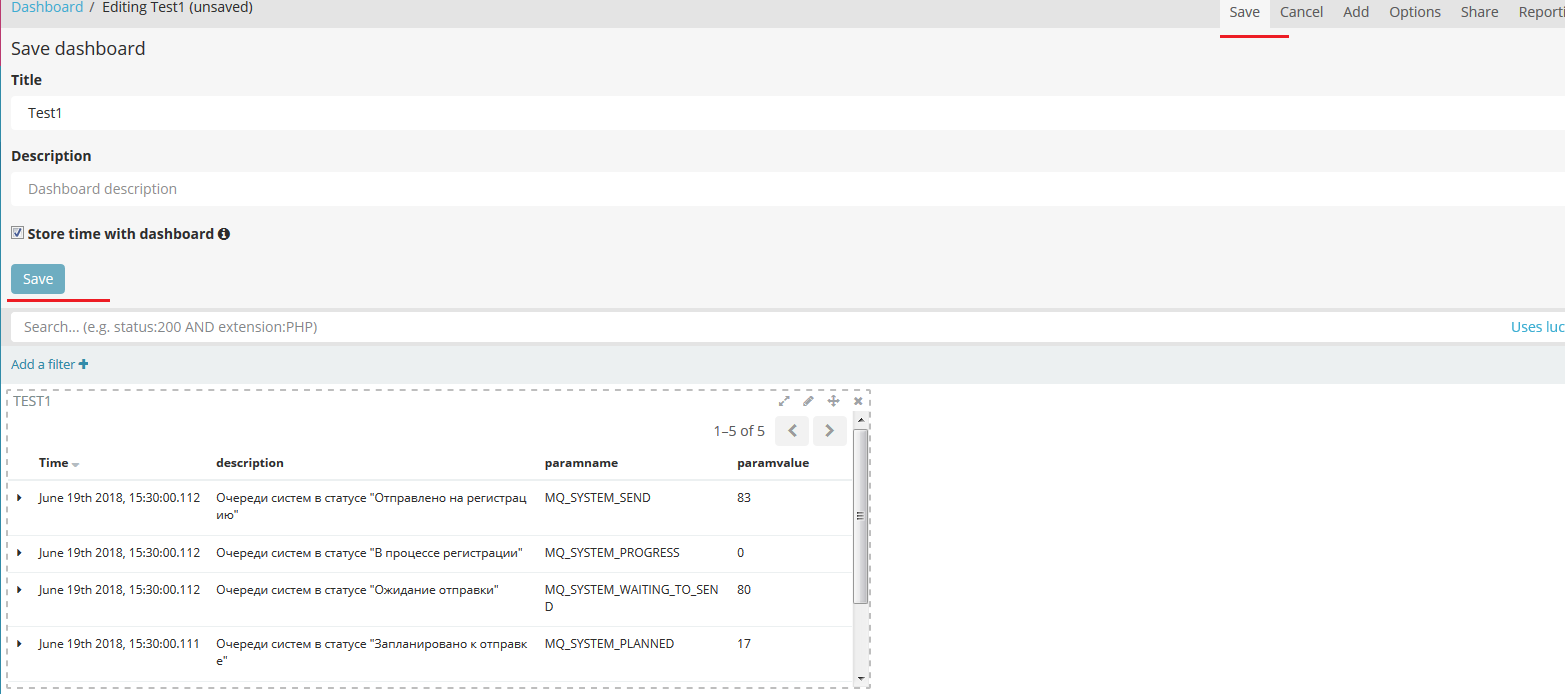
Затем переходим в пункт меню Save, указываем значение поля Title и Description, флажок Store time with dashboard – если хотим, чтобы показатели в дашборде обновлялись вместе с его загрузкой. Нажимаем на кнопку Save.
Создается Dashboard, который затем доступен в списке.
файл с sql-запросом: -v /u01/docker/logstash/queue-atm.sql:/usr/share/logstash/queue-atm.sql
Каталог с файлами, в которых настроены pipeline: -v /u01/docker/logstash/pipeline:/usr/share/logstash/pipeline
По умолчанию Logstash в каталоге /usr/share/logstash/pipeline все файлы воспринимает, как pipeline.
Образ Elasticsearch создан на основе официального образа docker.elastic.co/elasticsearch/elasticsearch:5.6.9.
В существующий образ внесены изменения согласно прилагаемому docker-файлy:
FROM docker.elastic.co/elasticsearch/elasticsearch:5.6.9
USER root
COPY ./limits.conf /etc/security/limits.conf
RUN chown -R elasticsearch:elasticsearch /usr/share/elasticsearch/data
RUN chown -R elasticsearch:elasticsearch /usr/share/elasticsearch/logs
USER elasticsearch
Где,
elasticsearch.yml – это конфигурационный файл.
/usr/share/elasticsearch/data – путь куда пишутся индексы
/usr/share/elasticsearch/logs – путь куда пишутся логи
limits.conf - cистемный файл /etc/security/limits.conf, в котором указаны настройки для пользователя elasticsearch: максимальное количество открытых файловых дескрипторов (nofile) и максимальное количество запущенных тредов (nproc).
Установить значение max virtual memory areas vm.max_map_count:
sysctl -w vm.max_map_count=262144
Кластер
Elasticsearch развернут в двух нодах.
Пример конфигурационного файла elasticsearch.yml для node1.
Пример конфигурационного файла elasticsearch.yml для node2.
Среди существующих планировщиков задач (IBM WebSphere Scheduler, EJB Timer Service, Quartz Scheduler, Spring Task Scheduler) предпочтение отдается Quartz Scheduler, так как он обладает рядом полезных свойств:
Хранение состояния задачи в БД (Персистентность)
Распределение нагрузки между серверами (Кластеризация)
Возможность гибкого задания расписания (cron, интервал)
Персистентность таймеров – важное необходимое свойство, включающее в себя следующее:
Сервер приложений сохраняет события планирования, когда приложение не работает, чтобы не потерять их.
Планировщик может быть настроен на сохранение пропущенных событий и их выполнение, когда приложение снова будет работать.
Сервер приложений использует внутреннюю базу данных для хранения пропущенных событий.
Примечание: сервер приложений будет генерировать все пропущенные события при рестарте приложения.
Очередь событий настраивается по частоте и задержке.
Есть возможность не сохранять события, которые были потеряны, если приложение не запущено – в таком случае таймеры будут являться неперсистентными.
В неперсистентном случае, жизненный цикл планировщика совпадает с приложением: создается при старте приложения и уничтожается по завершению приложения. Напротив персистентный планировщик выживает при рестарте приложения. Он просто спит, когда приложение не работает.
Примеры поведения персистентного планировщика:
Если триггер должен сработать только несколько раз. То после рестарта приложения Scheduler должен знать об этом и не активировать его.
Если у нас есть триггер, который должен срабатывать каждый час, но спустя, например, 59 минут наше приложение упало. То когда его перезапустили, этот триггер должен сработать через минуту, а не через час.
Что выбрать: персистентный или неперсистентный планировщик?
Если функциональность, выполняемая по расписанию, критична для бизнеса и мы не можем себе позволить потерять событие, то персистентный планировщик - решение проблемы.
В остальных случаях, неперсистентный планировщик легче (не использует БД) и проще в управлении (меньше трудностей при обновлении приложений, потому что не создается очередь планируемых событий при рестарте приложения, всегда создается новый планировщик при рестарте приложения).
Quartz предлагает два различных средства, с помощью которых можно хранить связанные с заданиями и триггерами данные в памяти или в базе данных:
Первое средство, экземпляр класса RAMJobStore, является настройкой по умолчанию. Это самое простое в использовании хранилище заданий, дающее к тому же наибольшую производительность, поскольку все данные хранятся в памяти. Главным недостатком этого метода является недостаточная сохраняемость данных. Поскольку все данные сохраняются в RAM, вся информация будет утеряна после “падения” приложения или системы.
Чтобы исправить эти недостатки, Quartz предлагает JDBCJobStore. Как следует из названия, этот способ сохранения заданий помещает данные в базу данных через JDBC. Ценой более надёжного хранения данных является более низкая производительность, а также большая сложность.
Дистрибутив quartz содержит скрипты для генерации таблиц для соответствующих баз в docs/dbTables.
Проблема:
В кластере запущено более чем один экземпляр нашего приложения (на каждый узел кластера) и все экземпляры имеют свои копии шедулеров. Но мы нуждаемся в одном шедулере, запущенном среди всех узлов кластера, в противном случае мы получаем множество копий одного и того же события.
Решение проблемы:
Каждый сервер приложений имеет свой вариант для решения проблемы “множества экземпляров шедулеров”.
Но общее решение требует сохраняемости (персистентности) шедулера при использовании в кластере. Т.к. нам нужно какое-то непереходное глобальное хранилище, чтобы отслеживать, какие задания выполнялись, чтобы они выполнялись точно на одной машине. Реляционная база данных как разделяемая память хорошо работает в этом сценарии.
Кластеризация в quartz позволяет решить две основные задачи:
Отказоустойчивость
Балансировка нагрузки
Кластеризация в quartz в настоящее время работает только с JDBC-Jobstore (JobStoreTX или JobStoreCMT), и основывается на том, что каждый узел в кластере работает с одной и той же базой.
Балансировка нагрузки происходит автоматически, на каждом узле кластера запускаются джобы так быстро как это возможно. Когда наступает время запуска триггера, первый узел, который овладевает им (размещает блокировку на нем), становится узлом, который запустит его. Только один узел запускает джобу для каждого старта. Т.е. если джоба имеет повторяющийся триггер, который говорит запускаться каждые 10 секунд, то только один узел стартует джобу в 12:00:00, затем в 12:00:10 и т.д. И необязательно, что это будет один и тот же узел каждый раз. Какой именно узел запускает джобу – определяется случайно. Механизм балансировки нагрузки является почти случайным для занятых шедулеров (у которых много триггеров), но поддерживает один и тот же узел для незанятых (несколько триггеров) планировщиков.
Отказоустойчивость случается, когда один узел падает в процессе выполнения одного или нескольких джоб. Когда узел падает, другой узел обнаруживает это состояние и определяет джобы в базе данных, которые были в процессе выполнения внутри упавшего узла. Каждая джоба, помеченная для восстановления (с значением свойства “requests recovery” в JobDetail), будет перевыполнена на оставшихся узлах. Джоба, непомеченная для восстановления, будет освобождена от выполнения в следующий раз при старте связанного триггера.
Кластеризация лучше всего подходит для масштабируемых долго-выполняемых и ресурсо-затратных джоб (распределяя загрузку работы среди множества узлов). Если вам необходимо горизонтально масштабировать поддержку тысячи часто запускаемых (1с) джоб, рассмотрите разделение джоб, используя множество различных планировщиков. Планировщик вынужден использовать кластерную блокировку. Паттерн который ухудшает производительность, когда вы добавляете больше узлов (свыше трех узлов – зависит от возможностей вашей базы данных).
Кластеризация включается установкой свойства «org.quartz.jobStore.isClustered» в значение true. Каждый экземпляр в кластере должен использовать одну и ту же копию файла quartz.properties. Исключением из этого является использование файлов, которые являются идентичными, со следующими допустимыми исключениями: различный размер пула потоков и различное значение для свойства org.quartz.scheduler.instanceId. Каждый узел в кластере должен иметь уникальный instanceId, который настраивается установкой значения «AUTO» в его свойство.
Никогда не запускайте кластеризацию на отдельных машинах, если их системы не синхронизируются регулярно по времени (часы должны быть в пределах секунды друг от друга).
Никогда не стартуйте некластеризованный экземпляр с тем же набором таблиц базы данных, что и любой другой экземпляр. Вы можете получить серьезное повреждение данных и неустойчивое поведение.
Пример properties-файла для кластеризованного планировщика:
Проблема:
Как управлять шедулером, не останавливая приложение: убирать из списка выполнения задачи или же менять cron-таймер и т.д.
Можно выделить два типа изменений:
Изменения не вовлекают джобы или удаление триггеров. Например, изменение крон-выражения для триггера, изменение параметров джобы, или java-класса для джобы.
Изменения, вовлекающие джобу или удаление триггера. Переименование джобы или триггера попадает в эту категорию.
Spring-овый ‘SchedulerFactoryBean’ поддерживает изменения первого типа: его свойство overwriteExistingJobs определяет, следует ли обновлять определения заданий и триггеров, хранящихся в базе данных, при запуске веб-приложения. По умолчанию используется значение false.
Изменения второго типа:
Если данное свойство установить в true, то старые джобы и триггеры не будут удалены, пока они не упоминаются в новой версии вашего приложения.
Возможны два способа решения проблемы:
Запустите сценарий базы данных перед установкой своего веб-приложения, которое уничтожит данные из таблиц (либо просто заданий и триггеров, которые будут удалены, либо все данные). Скрипт должен быть применен, когда приложения остановлены.
Реализуйте подкласс Spring SchedulerFactoryBean, который даст возможность очистить таблицы Quartz от Java при запуске веб-приложения
В Quartz у объекта шедулера можно вызывать следующие методы:
pauseJob(String name, String Group) — остановить выполнение задачи шедулера в указанной группе джобов. Остановка происходит путём остановки соответствующего триггера (см. pauseTrigger)
resumeJob(String name, String Group) — возобновить выполнение задачи шедулера в указанной группе джобов. Восстановление происходит путём запуска соответствующего триггера (см. resumeTrigger)
pauseTrigger(String name, String Group) — останавливает триггер в соответствующей группе
resumeTrigger(String name, String Group) — возобновляет работу триггера в соответсвующей группе
pauseAll — останавливает все задачи шедулера (pauseJobs(String group) — только у конкретной группы)
resumeAll — возобновляет запуск всех задач шедулера (см. также resumeJobs)
Интеграция Quartz + Spring
Spring обеспечивает поддержку классов Quartz и предоставляет следующие классы:
QuartzJobBean – простая реализация интерфейса org.quartz.Job, в которой необходимо реализовать метод executeInternal, в котором определяется действие для выполнения.
JobDetailFactoryBean – фабрика бинов для создания org.quartz.JobDetail. Вы можете сконфигурировать “job class” и “job data” используя bean-style.
SimpleTriggerFactoryBean – фабрика бинов для создания org.quartz.SimpleTrigger
CronTriggerFactoryBean – фабрика бинов для создания org.quartz.CronTrigger
SchedulerFactoryBean – фабрика бинов для создания org.quartz.Scheduler
Используя Quatz с WebSphere Application Server можно столкнуться с проблемами доступа к jndi-ресурсам или попытки участия в JTA-транзакции. Вы получаете эксепшн со следующим содержимым:
Exceptionjavax.naming.ConfigurationException: A JNDI operation on a “java:” name cannot be completed because the server runtime is not able to associate the operation’s thread with any J2EE application component. This condition can occur when the JNDI client using the “java:” name is not executed on the thread of a server application request. Make sure that a J2EE application does not execute JNDI operations on “java:” names within static code blocks or in threads created by that J2EE application. Such code does not necessarily run on the thread of a server application request and therefore is not supported by JNDI operations on “java:” names. [Root exception is javax.naming.NameNotFoundException: Name comp/env/[…] not found in context “java:”.]
Такие пакеты как quartz и jdk таймеры стартуют неуправляемые потоки. Неуправляемые потоки не имеют доступа к информации контекста JEE.
Для того, чтобы сделать Quartz полностью поддерживаемым в WebSphere необходимо быть уверенным, что неуправляемые потоки не стартуются. Тогда ваши джобы получают доступ к JNDI ресурсам и могут участвовать в JTA транзакциях (которые требуют поиска jndi java:comp/UserTransaction).
Это возможно благодаря указанию пользовательского thread pool (пула потоков), который делегирует CommonJ управление по созданию потоков. Однако, Quartz стартует несколько внутренних потоков, из которых стартуются актуальные джобы. Если внутренние quartz-потоки являются неуправляемыми, JEE контекст теряется и не может быть распространён на потоки джобов, даже если они являются управляемыми.
Две проблемы QTZ-113 «Quartz стартует неуправляемые потоки и J2EE контекст не распространяется на потоки джобов» и QTZ-194 «Quartz стартует неуправляемые потоки в JobStoreSupport» были исправлены в версии Quartz 2.1, который представляет новый интерфейс org.quartz.spi.ThreadExecutor.
Для того, чтобы внутренние quartz-потки были управляемыми необходимо установить два свойства в вашей конфигурации quartz:
Вы можете установить значение task executor в org.springframework.scheduling.commonj.WorkManagerTaskExecutor. Этот класс делегирует полномочия CommonJ Work Manager. Который доступен внутри WebSphere. Так потоки, которые будут созданы для ваших quartz-джобов, оборачиваются в commonj Work объекты, и будут управляться сервером приложений:
WorkManager в WorkManagerThreadPool инициализируется до старта планировщика из потока Java EE (таких как инициализация сервлета). WorkManagerThreadPool может затем создать поток-демон, который будет обрабатывать все планируемые задания по созданию и планированию новых Work-объектов. В этом случае планировщик (в своем собственном потоке) передает задачи потоку управления (Work-демону).
Т.е. всего два места где необходимо сконфигурировать quartz с commonj. Первое spring-конфиг, taskExecutor в SchedulerFactoryBean, второе определяется в property-файле в свойстве org.quartz.threadExecutor.class.
Настройка в spring позваляет quartz использовать пул потоков websphere для работы собственного пула потоков, настройка в property-файле используется для потока шедулера.